



According to the DBMS leaderboard - DB Engine (referred as DBE here onwards), PostgreSQL (referred as PG here onwards) is the 4th most popular relational database system in the market today, trailing behind other old guards such as Oracle, MySQL and SQL Server accordingly. DBE calculates popularity scores for hundreds of DBMSs by combining parameters such as number of mentions on the websites, search frequency, technical discussion frequency, job opportunities, community size and appearance in social media networks(e.g. twitter, quora, etc.). While DBE ranking does not include size of install base, the attributes used to calculate popularity often correspond linearly to the size of install base in most cases.
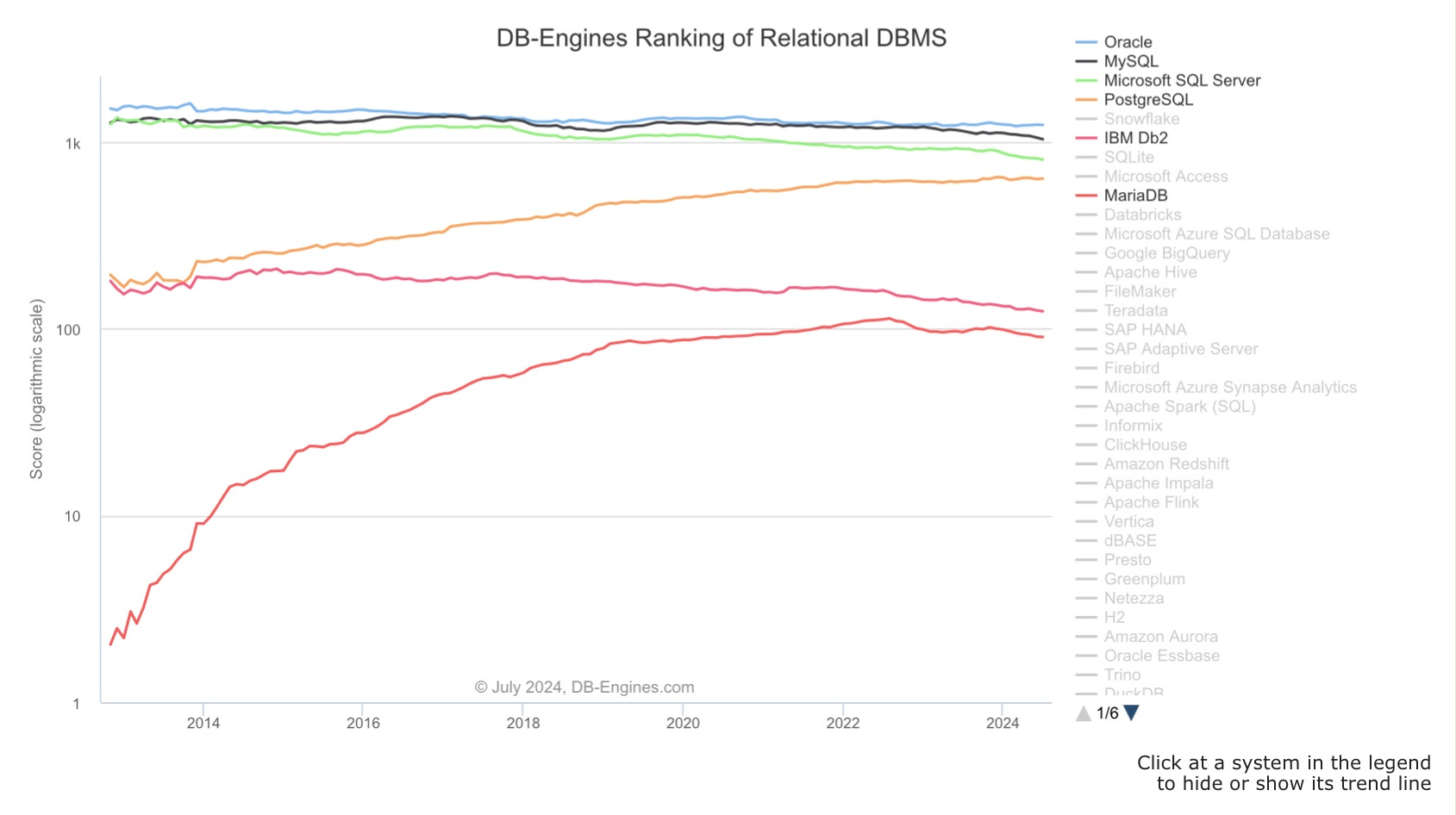
PG’s success in maintaining the top 5 position among these top runners is not accidental. Aside from maturing features of the native engine, PG constantly extended capabilities and interfaces over the years to support i) all types of data from - tabular, graph, time series, text, geospatial to vector embeddings (foreign data wrappers); ii) search; iii) data warehousing and analytics; iv) machine learning; v) and a variety of deployment modes - for public cloud DBaas, private cloud DBaas, on prem, and hybrid.
This act of continuously adding extensions, technology partners and foreign data wrappers strengthened offerings of the PG mothership, in line with its ‘Just use PG for everything’ marketing strategy. This move also drove countless PG adopters who initially adopted PG for custom solutions development or migrating out of legacy systems (system modernisation) to scale PG for other use cases without incurring the overhead of introducing a new technology. As a result, PG has become a common feature in data architectures for businesses small and large. Interestingly, regardless of the size of PG footprint, PG often plays a critical role in the overall end to end data architecture, where it sits as a moderator for data transformation between the legacy/old (rigid, monolithic, costly) and the newer systems (distributed, flexible, cheaper).
In this blog, we review how PG communities are reacting to PG’s latest strategies, lessons from past PG use cases, how PG’s current direction is aligning with data challenges faced by businesses and help data teams to increase value from their PG investments through simplification of various backends and front end systems.
2.0. Reaction from PG adopters and followers
PG has enjoyed 8 years of undisrupted popularity growth since 2015, along with the rise of public clouds. That growth is now slightly plateauing in the recent quarters despite various new announcements around performance and features including release of PG ML.
The ‘Just use PG for everything’ statement did stir some reaction in the community. Some are fully invested in the idea, quite a number raised doubts as they can’t imagine how this will look like in real world execution and some others raised concerns as they see it as an anti pattern to their current development practices (micro-services, polyglot dev environment, etc).
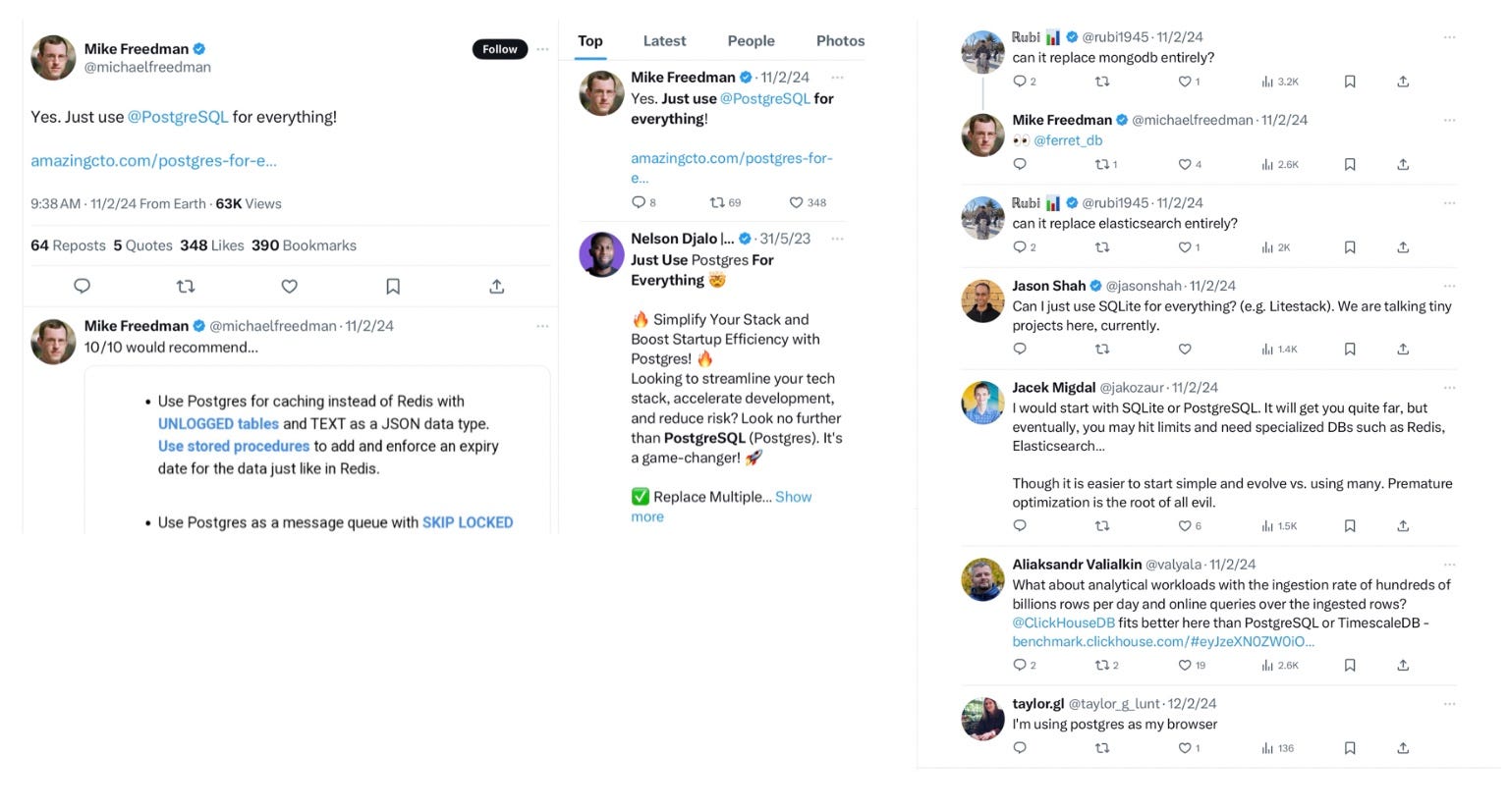
Small ventures.
Among all, smaller startups, early stage businesses and any other ventures with limited resources find this ‘one size fit for all’ strategy particularly appealing. Ability to stretch values from their PG investments to address a variety of data challenges using a generic DBMS solution to simplify backend and data pipelines is a great feature to this class of users. For this group, it’s expensive to prematurely isolate, abstract and optimise functions in their data processing and management architecture.
Old guard confonters.
A second group of PG followers consist of members who have deployed PG for various use cases such as migrating from legacy RDBMS (IBM, Oracle) to cut cost, migration out of document DBMS for faster queries and more analytic capabilities, or building new transactional applications. This group has been with PG for a while, first adopted PG for its ability to match Oracle or DB2 features, has a deep understanding of PGs architecture, product strategy to meet aspects of CAP ( scalability, availability, reliability, security), data types and operations supported. This group will continue to adopt PG as a quick route to modernise legacy apps and may not be particularly interested in the non-relational momentum. However, delivering effective tools for such modernisation tasks (mostly enterprise scale) is critical for PG in reclaiming the install base from other established RDBMS players.
Post cloud followers.
The third group of PG followers consist of members who adopted PG through cloud services such as Amazon RDS, Azure Postgres, Google Cloud SQL, Heroku Postgres, etc. This group uses PG as a service, delivered by cloud vendors as part of a multi modal data cloud service to support polyglot dev environment and microservices architecture. Many in this group apply constraints on the type of data/DBMS services used for development through their internal dev portal to streamline and optimise productivity. This group selects data services preemptively (through experimentation) before enabling them for their development communities and certainly does not correspond to the ‘one size fit all’ scheme. However, this is where PG will find its sweet spot with highest potential for footprint expansion. Reason - when data clouds expose a void in service (.eg. Geospatial, vector embeddings support) or inferior services for certain types of data, PG provides a way out to users without having to ever leave the data cloud. Question is - can PG meet and exceed the bar of cloud providers?
3.0. PG before Cloud
PG made its first debut during the peak of the Oracle RDBMS era. It was created to be an antidote for businesses (mostly a business pressure for small and SMB businesses) suffering from high DBMS licensing cost and businesses that struggled to contain cost for new projects and experiments. PG’s strategy back then was simple - to be an alternative to commercial and open source RDBMS.
An alternative to Old Guard RDBMS and MySQL.
PG’s initial product roadmap was determined by studying feature requests from a small group of user communities and their use cases. A significant number of these user communities also deployed solutions on Oracle and are familiar with Oracle RDBMS. Conversation with these user groups often lead to PG being compared against the gold standards of Oracle from basic RDBMS capabilities (ACID, multi version concurrency, referential integrity, transaction, locking, etc), to storage engine, access control, partitioning, indexing and supported interfaces. To bridge the gap PG dev team aligned product roadmap closely with Oracle’s and other commercial RDBMS features. Similarly when Oracle acquired MySQL, developer communities were uncertain of MySQL’s future and turned to PG to continue on the open source path.
Open Source.
On one end PG was just playing catch up with leading commercial RDBMS in terms of capabilities and on another enforced messaging that not all applications benefit from the rich set of features bundled in commercial RDBMS.
Developers' trust in open source was still lukewarm back then, though developer communities from all types of businesses were excited to experiment, especially with new projects. It wasn’t long before everyone realised that the cost savings made from eliminating licensing is now spent on resources elsewhere in data management, not to mention the operational complexities involved in keeping open source systems stable (availability, consistency, etc) for users. Aside from skills, the database features were the other concern for many users who’re already familiar with the feature-rich Oracle and DB2 RDBMS. As a result, users took a cautious approach to stay on PG and the open source path, mostly for smaller in-house projects and continued to invest in database licences from Oracle, Microsoft and IBM throughout the 90s and early millenium.
Professional Services and ISVs.
Successful adoption relied on a small group of professional services partners set to help users with mostly on premise deployment and train their internal teams to support, operate and maintain PG operations. At this same period, some large ISVs were exploring different strategies to reduce reliance on major RDBMs distributors by building their own databases (e.g.SAP/Hana) or including support for open source databases such as PG. Cost, data portability, business risk and the changing market dynamics were some of the reasons for this move.
4.0. PG Post Cloud
The uncertain pre-cloud open source PG picture changed after the 2015s, thanks mostly to cloud service providers such as AWS and Alibaba for offering a variety of initial services for PG ranging from fully managed to self managed PG deployments. For the first time, businesses were able to run PG powered apps or services on any cloud with zero or minimal migration impact and need not manage infrastructure, storage, network or other mundane routines. This freedom to choose deployment style, scale with demand, promise of DBMS licensing elimination boosted PG adoption in all segments of the market. Since then, PG’s popularity took a fast track and more than doubled as opposed to its closest open source rival MySQL.
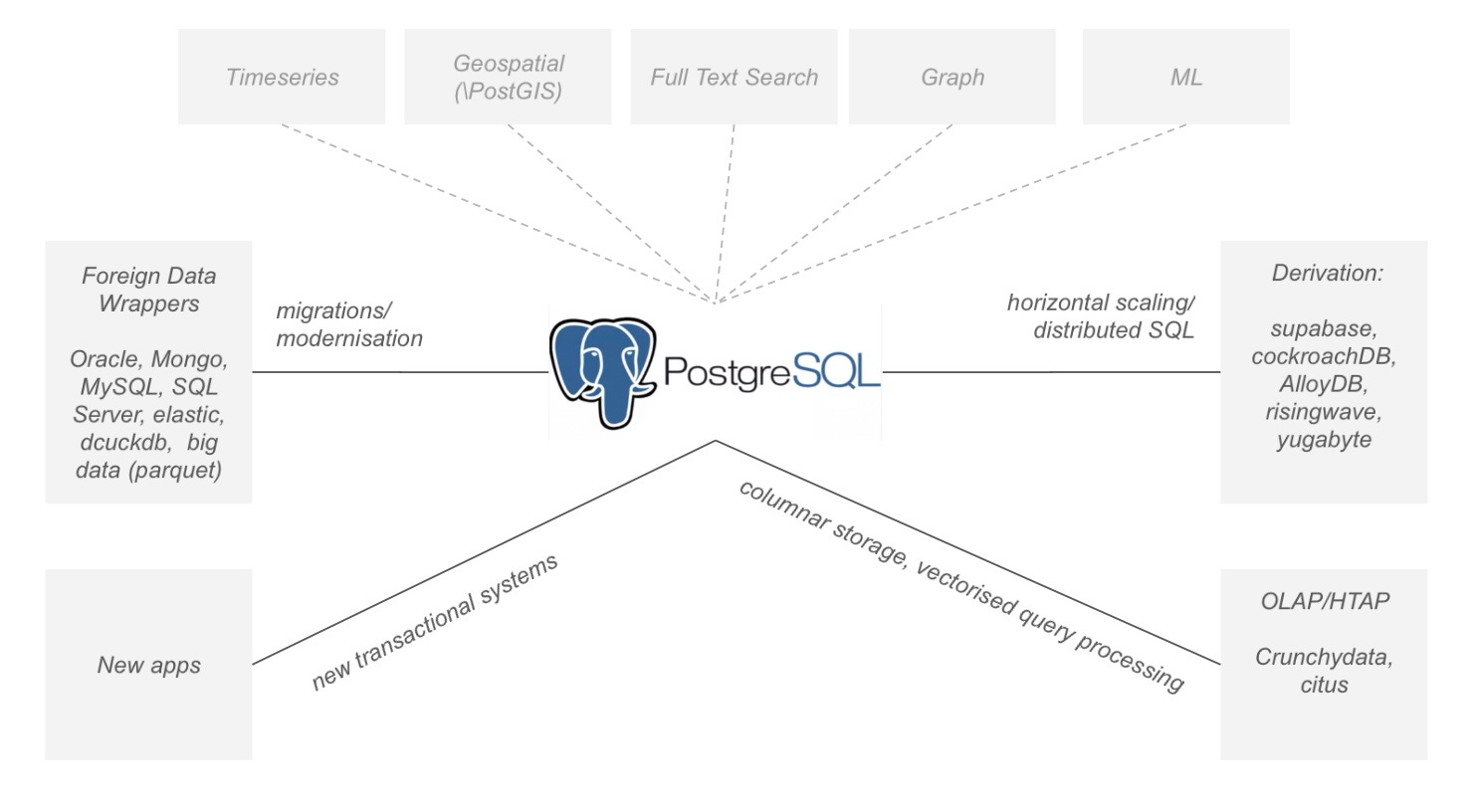
Refreshed technology.
Today PG is a multimodal database supporting graph, spatial, structural and vector models which can be deployed on cloud, on premise or in hybrid mode. PG’s current product roadmap is focused more on perceiving multi modality through extensions, cloud, AI/ML spectrum of capabilities and big data processing.
Cloud driven Adoption.
User communities have grown significantly as internet startups (e.g. Skype, Instagram, Reddit, and geni.com ) and cloud vendors (aws, GCP, azure, alibaba) run scalable services on PG for their global client base. PG is still a popular choice for enterprises when migrating out of commercial RDBMS as part of their digital transformation initiatives. PG is the DBMS of choice when building custom OLTP applications with ACID transactions for countless ISVs. Partner ecosystems ranging from professional services partners, cloud service partners to technology partners, amplified the effects by providing efficient support for PG adoption and operations. The fluid data portability between cloud platforms, lesser operational complexity, hybrid deployment styles and lower cost are all reasons for this outstanding response from user and partner communities everywhere.
Partner ecosystem.
Today, the profile of competition has changed for PG. It competes with both a range of commercial and open source DBMS in relational (SQL) and non-relational space (time series, document, geo spatial, vector embeddings). PG’s strategy towards competition is to build bridges with specialised collaborators in the big data space ( e.g. crunchydata, timescale, etc). This allows PG to add and deliver new capabilities and offerings to customers quickly and in a cost efficient manner. By taking this approach, PG can continue to meet demands of its users and meet gaps in data services of some of its cloud partners.
5.0. What really matters to Data Professionals ?
Among the elaborate list of PG refreshes and innovations - the following holds the highest relevance and is considered crucial for data professionals.
Data cloud services (Public Dbaas).
Public data cloud services for PG (aws, gcp, azure, etc) includes a range of offerings from native, derived and extension categories to meet demands of relational systems. Adoption is simplified, users can choose between managed PG instances or serverless options. The former allows users to adjust CPU, RAM, storage amount and speed. The latter automatically adjusts computing resources based on application requirements, completely liberating the tech teams to focus on the services instead of the management of the data layer. Most importantly, all users, regardless of geographic location, have sufficient access to cost effective, enterprise grade SQL services for delivering cloud/transactional applications.
Private data cloud services (Private Dbaas).
Partner offerings such as Aiven for PostgreSQL, helps large tech organisations in FSI, communication and internet businesses to implement their own private data cloud services for PG (among other DBMS services). These organisations have large dev teams responsible for managing and delivering digital products used by internal and external customers. For this class of businesses, it is imperative to privatise the ‘dbaas’, where the internal data team is responsible for delivering, monitoring and managing access to PG services through developer portals. These private ‘dbaas’ services include instances fully managed by the internal data team and instances subscribed from public ‘dbaas’ providers.
Support for data languages.
PG sufficiently supports all critical data (OLTP/OLAP) and ML languages e.g. SQL, Python, Malloy, Javascript, C++ and etc.
Predominantly RDBMS and generic enough to engulf various legacy and non legacy backend.
PG will continue to be a popular favourite for transactional or relational systems. In addition, the various extensions for JSON, XML and search makes it ideal for transitioning out of systems with rigid features, high cost or ceased to meet business needs. As a result, PG is often a choice made to slowly engulf backend systems sitting on Oracle, MySQL, SQL Server, SQLite, Mongo, Redis, Elastic and other big data sources (e.g. parquet). In these cases, users can choose to stay on native PG and extend or move on to other systems in derived category (e.g. supabase, OLAP)
Support for modern DW and Analytic.
PG does come with a querying layer and has good support for complex data types, and windows functions. Moreover, custom functions allow users to add custom data types. All of which is critical for a good analytic foundation, though by design PG is still a robust OLTP and is still not ideal for large scale DW. This is where PG OLAP extensions and derivatives such as Redshift, ParadeDB and Crunchy Data complement and complete analytics offerings for PG. PG users can realise columnar data storage, vectorised data processing and fast analytic queries through these partner technologies. These architectures make way for HTAP and delta lake integration for near real time data processing and insights.
AI and Machine Learning.
PostgresML takes a unified SQL-ML approach to machine learning tasks where users can opt to call ML models through a database query. The unified SQL-ML declarative language supports ML queries within the database without having to migrate data between different runtimes or platforms. PostgresML allows users to train, fine-tune, and deploy machine learning models with SQL SELECT statements. This empowers the PG community to scale ML values for businesses even without extensive knowledge in machine learning frameworks. Users can call pretrained models (e.g. Bert, llama) through integration with HuggingFace or train their own models by deploying a wide range of algorithms (e.g. Scikit-learn, XGBoost, LGBM, PyTorch, and TensorFlow). All within PG where the ML execution logic is abstracted from the DBMS implementation to support both AI operators (Linear Algebra) and database operators (Relational Algebra).

Data Portability.
The many PG native and derivative systems in the PG eco-system have another unique value rarely mentioned by anyone. It makes data very portable between cloud platforms and in migration paths. Data can be moved with zero to minimal change and migration cost from one system to another.
Conclusion - Multi-modal DBMS or a multi-modal data cloud?
The term ‘Just use PG for everything’ is an anti-pattern to those embracing polyglot development and microservices architecture. Nevertheless, for early stage businesses with limited resources this strategy may present unique opportunities to keep their development processes streamlined and optimised for highest productivity. Whereas for larger operations this approach is less ideal and may present risks. Plus building on microservices architecture and maintaining high dev productivity in a polyglot environment requires a” multi modal data cloud” not a “multi modal DBMS”. Though PG’s effort and track record to be friendly and collaborate with many leading new data startups (e.g. supabase, duckdb, Malloy, etc) to complete DBMS offerings is highly commendable and impressive. Which means PG’s evolution from PG multimodal to platform and a service cloud is inevitable.
Nonetheless, users small and large will continue PG adoption and for now, plug it somewhere in the middle of their end to end data architecture (on public cloud and private cloud) to simplify data pipelines in the backends and downstream systems. Leveraging opportunities to increase modernisation, data utility, retiring tech debt and scaling values of new tech especially in big data processing, ML and analytics space.
References
https://planet.postgresql.org
https://postgresml.org