Strategies for carbon efficient big data processing
Combining accurate performance prediction and modern data stack for cleaner architectures

Machine learning is taking cloud consumption to the next stage.
By 2025, cloud computing is projected to consume 20% of global electricity and emit up to 5.5% of the world’s carbon emissions. Over the last few years, cloud computing enabled businesses to leverage cloud services including technologies such as machine learning, deep learning and distributed computing to build and deploy innovative data intensive services at lightning speed. This resulted in rapid business growth but at the same time increased utilisation levels of virtualized computing resources including servers, cooling and brown energy which are both expensive and are becoming increasingly limited.
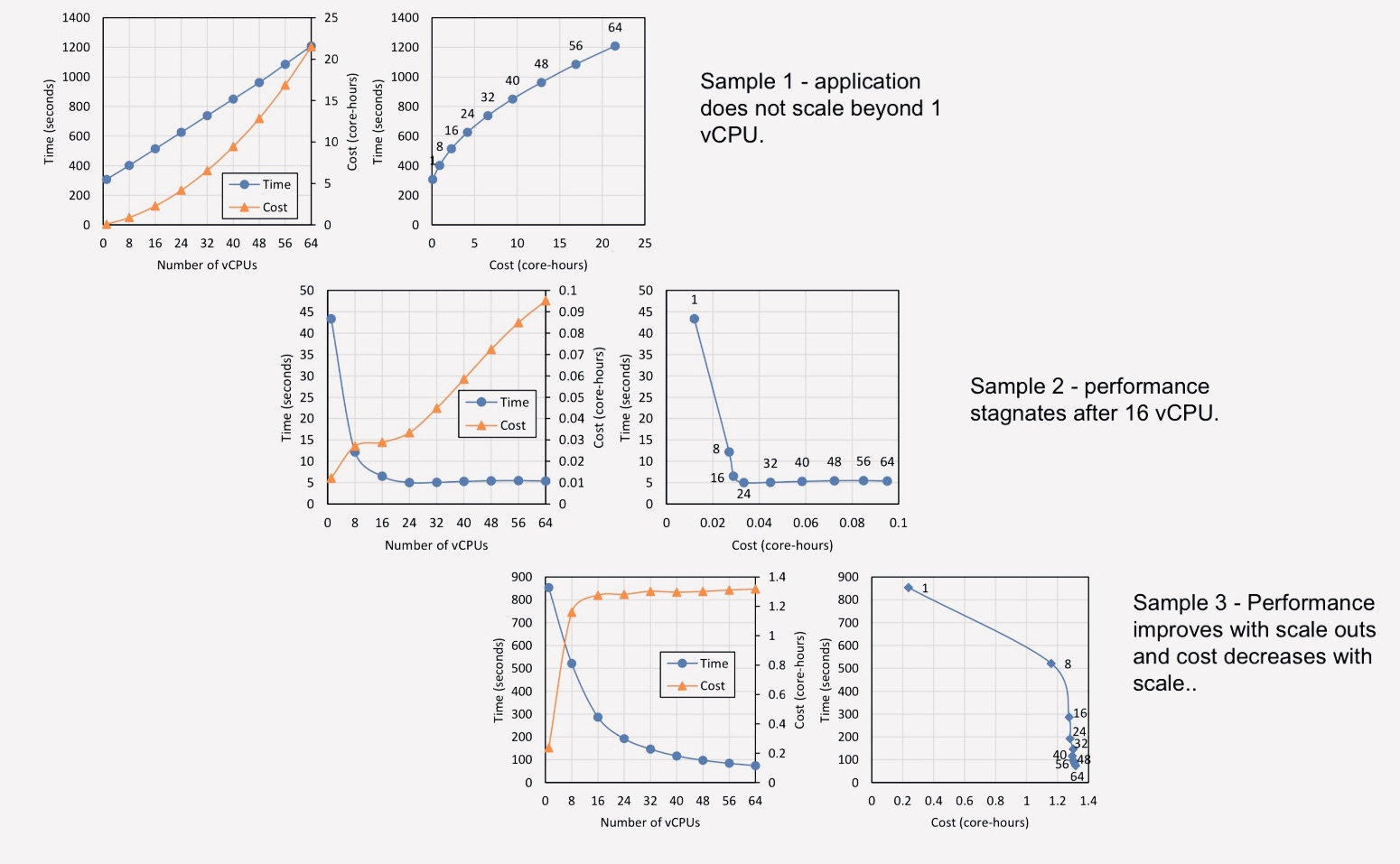
Despite the elastic nature of cloud computing most cloud users still overprovision resources by 50 to 80% for priority systems in fear of miscalculating required performance and missing deadlines. This is because predicting runtime performance, the right cloud VM type and scale out options for data processing clusters is not an easy task. Plus benchmarking 100s of VMs and jobs can be both expensive and time consuming especially for smaller teams.
Winners act within the value window and predefined budgets.
Not all data is created equal but typically value for most data diminishes with time. Reasons why big data processing routines have a finite timeline to deliver ready data to consumers such as machine learning, deep learning, OLAP queries, data analysis, recurring and one off real time or batch jobs. Processing millions and trillions of bytes of incoming data within a short value window and limited budget, requires engineers to correctly estimate runtime performance, computing resources (compute, memory, storage and network bandwidth) and scale out options for meeting runtime goals (e.g. duration, cost).
While it is possible for experienced engineers to use conventional methods of trial and error experimentation or benchmarking selected VMs recommended by cloud vendors to search for the required performance and cluster configuration, this method scales poorly, is error prone, resource intensive and expensive when workloads are highly heterogeneous and teams are decentralised.
Meeting data processing deadlines by constantly throwing more compute resources is a recipe for disaster which will sharply decrease profitability and accelerate information catastrophe, even when business is in midst of rapid growth. Whereas, frequently missing data processing deadlines on the contrary, turns data into liability which continues to squander valuable resources and contributes to carbon emissions.

These factors make capability to predict runtime performance accurately for big data applications critical in determining the right VM type, compute resources (cores, memory, disk I/O, storage, network bandwidth) and cluster configuration (scale out options) for various data related services. Furthermore, a uniformed method to make predictions with high confidence levels can empower technology teams with the assurance needed to schedule work with fewer resource buffers which turns into a key business differentiator when extrapolated to entire technology operation.
Understanding attributes shaping resource requirements.
Applications. Cloud and internet has changed the way we design and deploy applications, services and analytics. Shifting from monolith to n-tier and microservices architecture, leveraging the increasingly distributed and parallel computing paradigm, each application has its own technology stack and parameters defining limitations and threshold for scalability and processing throughput (apparent only to developers and not deployment or optimisation team).